Looking at your Data
2025-08-22

“The most certain sign of wisdom is cheerfulness.”
— Michel de Montaigne, Writer and philosopher
Plot Fonts and Theme
Code
library(systemfonts)
library(showtext)
## Clean the slate
systemfonts::clear_local_fonts()
systemfonts::clear_registry()
##
showtext_opts(dpi = 96) # set DPI for showtext
sysfonts::font_add(
family = "Alegreya",
regular = "../../../../../../fonts/Alegreya-Regular.ttf",
bold = "../../../../../../fonts/Alegreya-Bold.ttf",
italic = "../../../../../../fonts/Alegreya-Italic.ttf",
bolditalic = "../../../../../../fonts/Alegreya-BoldItalic.ttf"
)
sysfonts::font_add(
family = "Roboto Condensed",
regular = "../../../../../../fonts/RobotoCondensed-Regular.ttf",
bold = "../../../../../../fonts/RobotoCondensed-Bold.ttf",
italic = "../../../../../../fonts/RobotoCondensed-Italic.ttf",
bolditalic = "../../../../../../fonts/RobotoCondensed-BoldItalic.ttf"
)
showtext_auto(enable = TRUE) # enable showtext
##
theme_custom <- function() {
theme_bw(base_size = 10) +
#
# theme(panel.widths = unit(11, "cm"),
# panel.heights = unit(6.79, "cm")) + # Golden Ratio
theme(
plot.margin = margin_auto(t = 1, r = 2, b = 1, l = 1, unit = "cm"),
plot.background = element_rect(
fill = "bisque",
colour = "black",
linewidth = 1
)
) +
theme_sub_axis(
title = element_text(
family = "Roboto Condensed",
size = 10
),
text = element_text(
family = "Roboto Condensed",
size = 8
)
) +
theme_sub_legend(
text = element_text(
family = "Roboto Condensed",
size = 6
),
title = element_text(
family = "Alegreya",
size = 8
)
) +
theme_sub_plot(
title = element_text(
family = "Alegreya",
size = 14, face = "bold"
),
title.position = "plot",
subtitle = element_text(
family = "Alegreya",
size = 10
),
caption = element_text(
family = "Alegreya",
size = 6
),
caption.position = "plot"
)
}
## Use available fonts in ggplot text geoms too!
ggplot2::update_geom_defaults(geom = "text", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
ggplot2::update_geom_defaults(geom = "label", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
ggplot2::update_geom_defaults(geom = "marquee", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
ggplot2::update_geom_defaults(geom = "text_repel", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
ggplot2::update_geom_defaults(geom = "label_repel", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
## Set the theme
ggplot2::theme_set(new = theme_custom())
## tinytable options
options("tinytable_tt_digits" = 2)
options("tinytable_format_num_fmt" = "significant_cell")
options(tinytable_html_mathjax = TRUE)
## Set defaults for flextable
flextable::set_flextable_defaults(font.family = "Roboto Condensed")
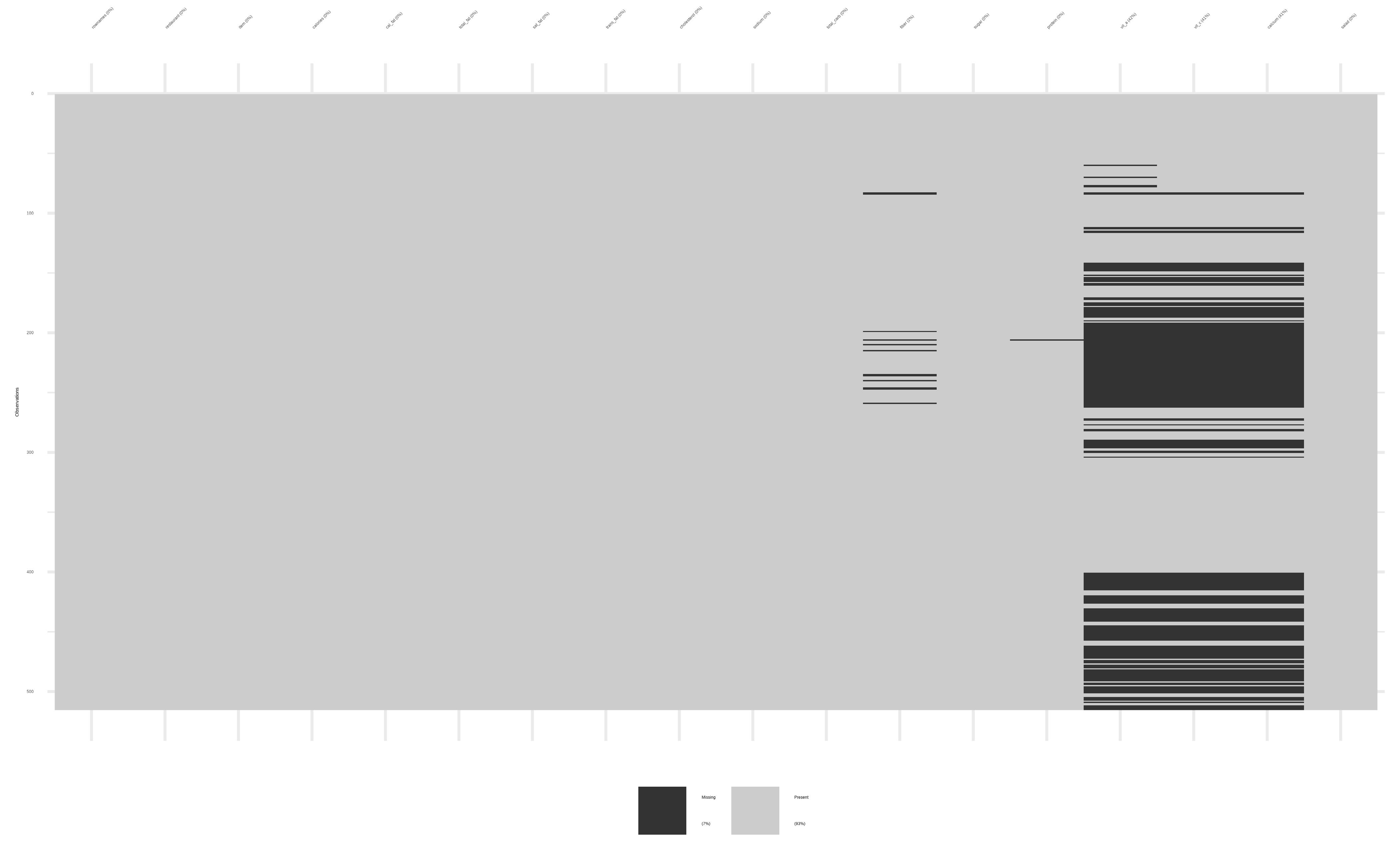
Let us use the {visdat} package to visualize this:
Code

Arel-Bundock, Vincent. 2026. tinytable: Simple and Configurable Tables in “HTML,” “LaTeX,” “Markdown,” “Word,” “PNG,” “PDF,” and “Typst” Formats. https://doi.org/10.32614/CRAN.package.tinytable.
Firke, Sam. 2024. janitor: Simple Tools for Examining and Cleaning Dirty Data. https://doi.org/10.32614/CRAN.package.janitor.
Rennie, Nicola. 2024. messy: Create Messy Data from Clean Data Frames. https://doi.org/10.32614/CRAN.package.messy.
Tierney, Nicholas. 2017. “visdat: Visualising Whole Data Frames.” JOSS 2 (16): 355. https://doi.org/10.21105/joss.00355.
Tierney, Nicholas, and Dianne Cook. 2023. “Expanding Tidy Data Principles to Facilitate Missing Data Exploration, Visualization and Assessment of Imputations.” Journal of Statistical Software 105 (7): 1–31. https://doi.org/10.18637/jss.v105.i07.
Xie, Yihui, Joe Cheng, Xianying Tan, and Garrick Aden-Buie. 2025. DT: A Wrapper of the JavaScript Library “DataTables”. https://doi.org/10.32614/CRAN.package.DT.