Where does Data come from, what does it look like

“Difficulties strengthen the mind, as labor does the body.”
— Seneca
1
Plot Fonts and Theme
Show the Code
library(systemfonts)
library(showtext)
library(ggrepel)
library(marquee)
## Clean the slate
systemfonts::clear_local_fonts()
systemfonts::clear_registry()
##
showtext_opts(dpi = 96) # set DPI for showtext
sysfonts::font_add(
family = "Alegreya",
regular = "../../../../../../fonts/Alegreya-Regular.ttf",
bold = "../../../../../../fonts/Alegreya-Bold.ttf",
italic = "../../../../../../fonts/Alegreya-Italic.ttf",
bolditalic = "../../../../../../fonts/Alegreya-BoldItalic.ttf"
)
sysfonts::font_add(
family = "Roboto Condensed",
regular = "../../../../../../fonts/RobotoCondensed-Regular.ttf",
bold = "../../../../../../fonts/RobotoCondensed-Bold.ttf",
italic = "../../../../../../fonts/RobotoCondensed-Italic.ttf",
bolditalic = "../../../../../../fonts/RobotoCondensed-BoldItalic.ttf"
)
showtext_auto(enable = TRUE) # enable showtext
##
theme_custom <- function() {
theme_bw(base_size = 10) +
theme_sub_axis(
title = element_text(
family = "Roboto Condensed",
size = 8
),
text = element_text(
family = "Roboto Condensed",
size = 6
)
) +
theme_sub_legend(
text = element_text(
family = "Roboto Condensed",
size = 6
),
title = element_text(
family = "Alegreya",
size = 8
)
) +
theme_sub_plot(
title = element_text(
family = "Alegreya",
size = 14, face = "bold"
),
title.position = "plot",
subtitle = element_text(
family = "Alegreya",
size = 10
),
caption = element_text(
family = "Alegreya",
size = 6
),
caption.position = "plot"
)
}
## Use available fonts in ggplot text geoms too!
ggplot2::update_geom_defaults(geom = "text", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
ggplot2::update_geom_defaults(geom = "label", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
ggplot2::update_geom_defaults(geom = "marquee", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
ggplot2::update_geom_defaults(geom = "text_repel", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
ggplot2::update_geom_defaults(geom = "label_repel", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
## Set the theme
ggplot2::theme_set(new = theme_custom())
## tinytable options
options("tinytable_tt_digits" = 2)
options("tinytable_format_num_fmt" = "significant_cell")
options(tinytable_html_mathjax = TRUE)
## Set defaults for flextable
flextable::set_flextable_defaults(font.family = "Roboto Condensed")
1.1
This tutorial uses web-r that allows you to run all code within your browser, on all devices. Most code chunks herein are formatted in a tabbed structure ( like in an old-fashioned library) with duplicated code. The tabs in front have regular R code that will work when copy-pasted in your RStudio session. The tab “behind” has the web-R code that can work directly in your browser, and can be modified as well. The R code is also there to make sure you have original code to go back to, when you have made several modifications to the code on the web-r tabs and need to compare your code with the original!
1.2 Keyboard Shortcuts
- Run selected code using either:
- macOS: ⌘ + ↩︎/Return
- Windows/Linux: Ctrl + ↩︎/Enter
- Run the entire code by clicking the “Run code” button or pressing Shift+↩︎.
All embedded figures are displayed full-screen when clicked.
2 Where does Data come from?
We will need to form a basic understanding of basic scientific enterprise. Let us look at the slides. (Also embedded below!)
3


Each variable is a column; a column contains one kind of data. Each observation or case is a row.
4 How do we Spot Data Variable Types?
By asking questions! Shown below is a table of different kinds of questions you could use to query a dataset. The variable or variables that “answer” the question would be in the category indicated by the question.
4.1 Variables and Operations
| No | Pronoun | Answer | Variable/Scale | Example | What Operations? |
|---|---|---|---|---|---|
| 1 | How Many / Much / Heavy? Few? Seldom? Often? When? | Quantities, with Scale and a Zero Value.Differences and Ratios /Products are meaningful. | Quantitative/Ratio | Length,Height,Temperature in Kelvin,Activity,Dose Amount,Reaction Rate,Flow Rate,Concentration,Pulse,Survival Rate | Correlation |
| 2 | How Many / Much / Heavy? Few? Seldom? Often? When? | Quantities with Scale. Differences are meaningful, but not products or ratios | Quantitative/Interval | pH,SAT score(200-800),Credit score(300-850),SAT score(200-800),Year of Starting College | Mean,Standard Deviation |
| 3 | How, What Kind, What Sort | A Manner / Method, Type or Attribute from a list, with list items in some " order" ( e.g. good, better, improved, best..) | Qualitative/Ordinal | Socioeconomic status (Low income, Middle income, High income),Education level (HighSchool, BS, MS, PhD),Satisfaction rating(Very much Dislike, Dislike, Neutral, Like, Very Much Like) | Median,Percentile |
| 4 | What, Who, Where, Whom, Which | Name, Place, Animal, Thing | Qualitative/Nominal | Name | Count no. of cases,Mode |
4.2 Variables and Hierarchy
As you go from Qualitative to Quantitative data types in the table, I hope you can detect a movement from fuzzy groups/categories to more and more crystallized numbers.
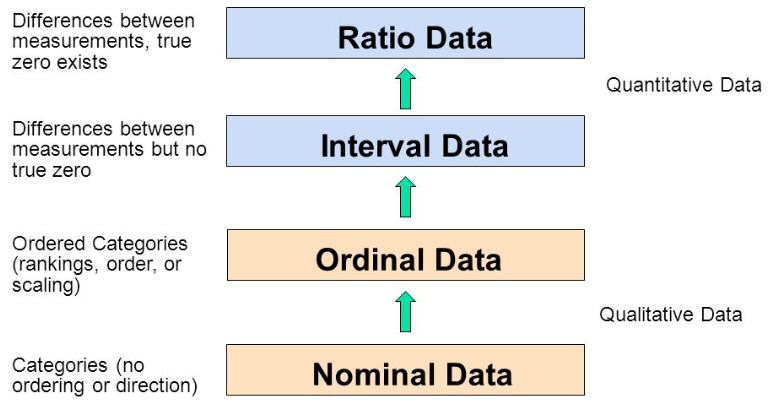
Each variable/scale can be subjected to the operations of the previous group. In the words of S.S. Stevens
the basic operations needed to create each type of scale is cumulative: to an operation listed opposite a particular scale must be added all those operations preceding it.
5 Some Examples of Data Variables
5.1 Example 1: AllCountries
Q1. How many people in Andorra have internet access?
A1. This leads to the Internet variable, which is a Quantitative variable, a proportion.1 The answer is \(70.5\%\).
5.2 Example 2:StudentSurveys
head(StudentSurvey, 5)Q.1. What kind of students are these?
A.1. The variables Gender, and Year both answer to this Question. And they are both Qualitative/Categorical variables, of course.
Q.2. What is their status in their respective families?
A.2. Hmm…they are either first-born, or second-born, or third…etc. While this is recorded as a number, it is still a Qualitative variable2! Think! Can you do math operations with BirthOrder? Like mean or median?
Q.3.How big are the families?
A.3. Clearly, the variable that answers is Siblings and since the question is synonymous with “how many”, this is a Quantitative variable.
6
Let us take a look at Wickham and Grolemund’s Data Science workflow picture:

So there we have it:
- Data: We generate data by experiment, or obtain readily available data. We import and clean the data
- Variables: Questions lead us to identify Types of Variables (Quant and Qual)
- Transform: Sometimes we may need to transform the data (long to wide, summarize, create new variables…)
- Explore: Further Questions lead us to infer relationships between variables, the relative size of things, which we describe using Data Visualizations
- Report: This may be of interest, or best of all, outright surprising! Which is finally Communicated with charts and descriptions in a research report.
You might think of all these Questions, Answers, Mapping as being equivalent to a grammar, as a language in itself. And indeed, in R we use a philosophy called the Grammar of Graphics! We will use this grammar in the R graphics packages that we will encounter when we make Graphs next. Other parts of the Workflow (Transformation, Analysis and Modelling) are also following similar grammars, as we shall see.
7
This is a tutorial on data visualization using the R programming language. It introduces concepts such as data types, variables, and visualization techniques. The tutorial utilizes metaphors to explain these concepts, emphasizing the use of geometric aesthetics to represent data. It also highlights the importance of both visual and analytic approaches in understanding data. The tutorial then demonstrates basic chart types, including histograms, scatterplots, and bar charts, and discusses the “Grammar of Graphics” philosophy that guides data visualization in R. The text concludes with a workflow diagram for data science, emphasizing the iterative process of data import, cleaning, transformation, visualization, hypothesis generation, analysis, and communication.
7.1 Randomized Trials
These are the gold standard for experimental data. They involve randomly assigning subjects to treatment and control groups (e.g vaccine and no vaccine) to measure the effect of a treatment or intervention. This method helps eliminate bias and confounding variables, providing robust evidence for causal relationships.
8
- Martyn Shuttleworth, Lyndsay T Wilson (Jun 26, 2009). What is the Scientific Method? Retrieved Mar 12, 2024 from Explorable.com: https://explorable.com/what-is-the-scientific-method
- Adam E.M. Eltorai, Jeffrey A. Bakal, Paige C. Newell, Adena J. Osband (editors). (March 22, 2023) Translational Surgery: Handbook for Designing and Conducting Clinical and Translational Research. A very lucid and easily explained set of chapters. ( I have a copy. Yes.)
- Part III. Clinical: fundamentals
- Part IV: Statistical principles
- https://safetyculture.com/topics/design-of-experiments/
- Emi Tanaka. https://emitanaka.org/teaching/monash-wcd/2020/week09-DoE.html
- Open Intro Stats: Types of Variables
- Lock, Lock, Lock, Lock, and Lock. Statistics: Unlocking the Power of Data, Third Edition, Wiley, 2021. https://www.wiley.com/en-br/Statistics:+Unlocking+the+Power+of+Data,+3rd+Edition-p-9781119674160)
- Claus Wilke. Fundamentals of Data Visualization. https://clauswilke.com/dataviz/
- Tim C. Hesterberg (2015). What Teachers Should Know About the Bootstrap: Resampling in the Undergraduate Statistics Curriculum, The American Statistician, 69:4, 371-386, DOI:10.1080/00031305.2015.1089789. PDF here
8.1
Footnotes
Citation
@online{2021,
author = {},
title = {\textless Iconify-Icon Icon=“icon-Park-Twotone:data-User”
Width=“1.2em”
Height=“1.2em”\textgreater\textless/Iconify-Icon\textgreater{}
{Data}},
date = {2021-11-01},
url = {https://madhatterguide.netlify.app/content/courses/Analytics/10-Descriptive/Modules/05-NatureData/},
langid = {en}
}